近日,第63届国际计算语言学年会(ACL2025)公布了论文录用结果,我校计算机科学与技术学院刘那与老师3篇论文被录用,其中2篇论文被主会(Main Conference)接收,1篇论文被“Findings of ACL”录用。ACL年会是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会主办,在中国计算机学会(CCF)与中国人工智能学会(CAAI)中均被推荐为A类会议。
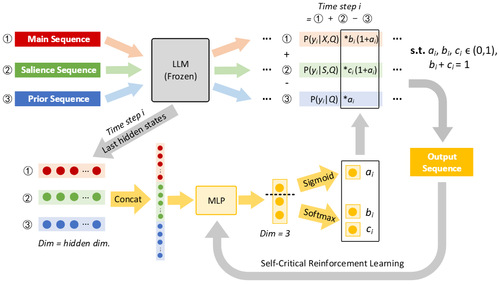
大语言模型(LLMs)在抽象摘要中虽提升流畅性与信息量,但易生成偏离原文的“幻觉”内容。近期的点互信息(PMI)解码策略通过对比有无源文档时输出概率,减弱模型先验知识依赖,提升上下文利用和摘要忠实度。现有方法常忽视显式显著信息建模,并依赖静态超参数平衡上下文与先验知识的关系。针对上述问题,《SARA: Salience-Aware Reinforced Adaptive Decoding for Large Language Models in Abstractive Summarization》(刘那与老师为第一作者)一文提出显著感知的强化适应解码(SARA),结合显著信息与PMI运算,动态调整源文档上下文、显著上下文与先验知识的权重,并通过强化学习实现逐词自适应解码,优化上下文与知识的动态分配。实验证明,SARA在CNN/DM、WikiHow和NYT50数据集和不同LLMs上始终提升摘要质量与忠实度。
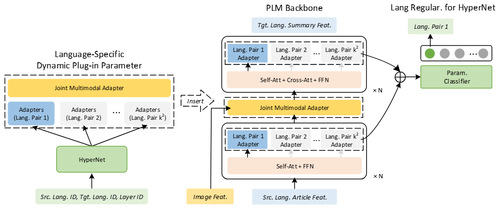
近年来,多对多语言多模态摘要(M3S)因其支持多语言输入输出的统一建模引起关注。现有方法在共享模型参数基础上转移通用MS知识的同时往往忽略语言特有知识,不同语言间可能产生干扰,限制模型对多语言组合灵活适应。《Language Constrained Multimodal Hyper Adapter For Many-to-Many Multimodal Summarization》(刘那与老师为第一作者)一文研究了多模态摘要(MS)通过融合文本与视觉信息生成更丰富的内容,提出语言约束的多模态超网络适配器(LCMHA),通过语言正则化超网络引导语言特定适配器融入多语言主干模型来放宽不同语言组合参数共享,结合共享多模态适配器保持不同语言适配器特征和公共视觉特征交互。实验表明,LCMHA在多种多语言预训练模型主干上展现出良好效果和可扩展性。
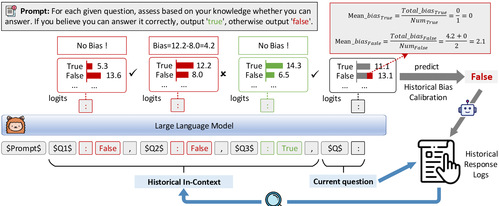
《Whether LLMs Know If They Know: Identifying Knowledge Boundaries via Debiased Historical In-Context Learning》(刘那与老师为第二作者)文章表明:在主动检索(AR)中,大语言模型(LLMs)需判断自己是否具备回答某一查询的知识,以决定是否调用检索模块。现有方法依赖分类器或模型置信度评估,泛化能力有限,且LLMs易受令牌语义等先验偏见干扰。本文提出去偏历史情境学习(DH-ICL),将知识边界识别这一自我意识的元认知任务重构为结构化模式学习任务,通过检索相似历史查询作为高置信度的上下文,引导知识边界识别;并引入历史偏差校准策略,通过收集模型过去回答的偏差来矫正当前知识边界评估中认知偏差。实验表明,DH-ICL在四个QA基准上实现与完整检索相当的性能,显著减少检索次数,且无需额外训练,并在冷启动场景中验证了其鲁棒性。
相关论文获国家自然科学基金、天津市自然科学基金及天津工业大学沧州研究院科研基金资助。
(审稿:计算机科学与技术学院 楼稚明 编辑:党委宣传部 张莘苑)
图片来源:计算机科学与技术学院

